
Fjall is an embeddable LSM-based forbid-unsafe Rust key-value storage engine. Its goal is to be a reliable & predictable but performant general-purpose KV storage engine.
2.5 is another performance focused update.
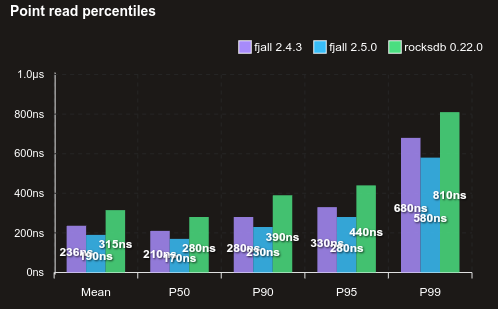
Using full block index for L0 and L1
Fjall uses a partitioned (two-level) block index. The top-level index is always fully loaded in memory, but is very small. The second level index is stored on disk and can be loaded partially as needed. This decreases memory usage for large databases, allowing more hot data to be cached instead. However, for an uncached read, a partitioned block index may incur 2 instead of 1 random read I/O. Because level 0 and 1 (L0 and L1) are very small, the memory savings in these levels are negligible.
Now, L0 and L1 segments will use the full block index.
Here is a benchmark of point reading 5M random KVs with virtually no block caching:
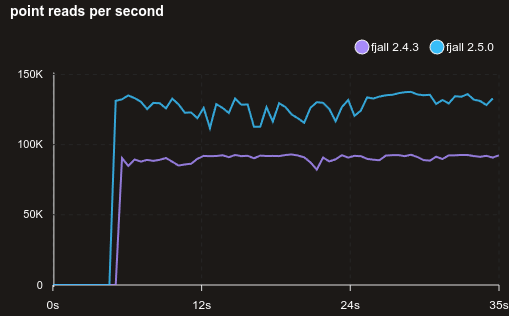

Fixed point reads for update-heavy workloads
Fjall uses MVCC (multi-version concurrency control) for snapshotting and transaction isolation. That means, every key may be in the database multiple times, stored from newest to oldest. Old versions are lazily deleted during compactions.
If there were very many versions for a single key, the memtable could end up reading too much versions when a snapshot is used. Now it always skips to the correct version, avoiding scanning through versions, which increased read latencies.
Here is a benchmark with 95% point reads and 5% updates of existing KVs:
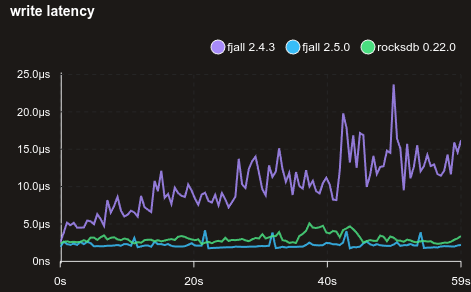
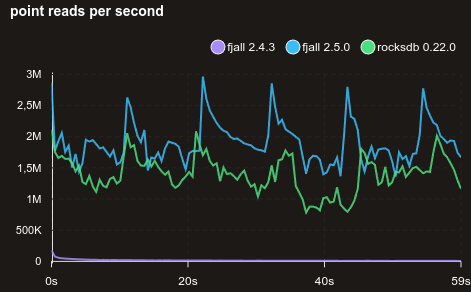
Lazily evaluate range bounds
When using a bounded range() (or prefix(), which is just a range() internally), lsm-tree would try to find the range bounds (the two blocks that make up the lower and upper bound of the range).
This requires two block index lookups, which could result in 2 read I/O’s if the blocks are not cached.
However, most of the time, a range is only read in one direction (either using next() or next_back()), so now:
- when using
next()the first time, the lower bound is initialized - when using
next_back()the first time, the upper bound is initialized
In low-cache scenarios, this can effectively double the setup cost of short range reads.
Parallel compactions in Leveled compaction strategy
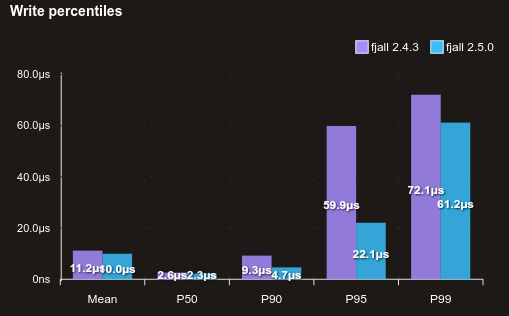
Previously, one compaction would fully lock its source and destination level, which blocks more compaction tasks being registered for those levels. If the compaction is slower than the ingestion of new data, write stalls may occur. Now, compactions granularly lock its portion of disk segments such that other compaction tasks can be registered in parallel, making more use of multi-core machines for write heavy workloads, and allows for more granular compactions, which decreases temporary space usage.
This benchmark writes rather large (1 kilobyte) values with random keys:
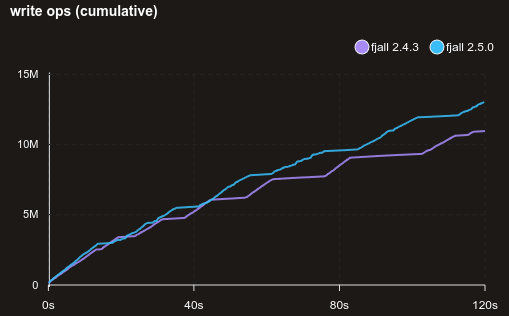
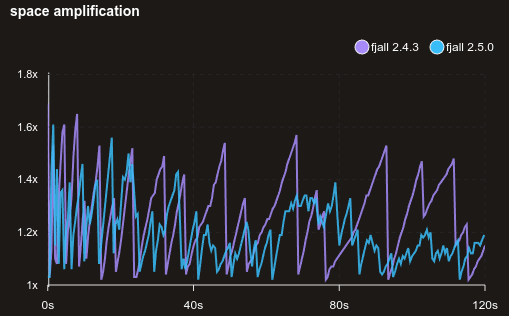
Shorter snapshot point read hot path
Further optimizations made the point read hot path a bit shorter. However this is not really noticable on large data sets, but gives a nice read boost for very small data sets.
Here is a benchmark with 100% random point reads of 1’000 KVs, all stored in the memtable:
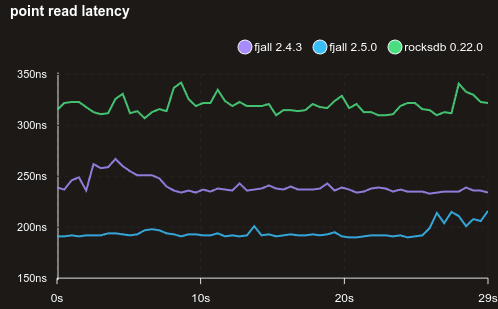
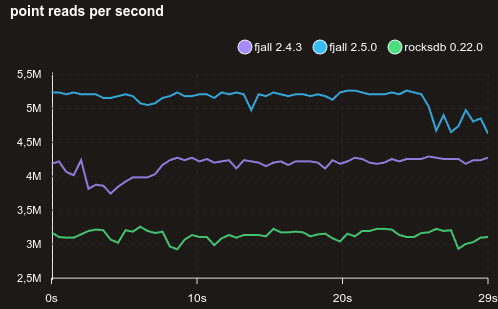
Avoiding heap allocation for insert operations
Write operations such as insert() and remove() previously used a AsRef<[u8]> trait bound.
While flexible, this trait bound would more or less force a heap allocation for every write operation.
Now, all write operations require a Into<Slice> as input, which can avoid that heap allocation, especially when using the new bytes feature flag.
With the trait bound being different now, some singular generic parameters may fail to compile, but hopefully the existing Into<_> implementations catch all common use cases, and makes the change worth it.
2.4
2.4 was a very small release that did not warrant its own blog entry.
Tokio Bytes support
Fjall 2.4+ now support the Tokio bytes crate as its underlying Slice implementation for keys and values, allowing better compatibility with projects that use bytes (especially actix-web and axum).
This can be enabled using the bytes feature flag.
Thanks to @carlsverre for implementing both the bytes feature flag and the Into<_> trait bounds.
size_of
Also, there is a new size_of function that is logically the same as db.get(key)?.len(); however, for a key-value separated tree it is more efficient as it does not need to read the blob from disk (because the size is stored in the index tree already).
Discord
Join the discord server if you want to chat about databases, Rust or whatever: https://discord.gg/HvYGp4NFFk
Interested in LSM-trees and Rust?
Check out fjall, an MIT-licensed LSM-based storage engine written in Rust.
