
Fjall is an embeddable LSM-based forbid-unsafe Rust key-value storage engine. Its goal is to be a reliable & predictable but performant general-purpose KV storage engine.
Bulk loading API
For bulk loading, we want fast insertion speeds of an existing data set. Because the data set already exists, we can insert in ascending order, which makes bulk loading faster. The write path of a naive LSM-tree is already notoriously short: Any write object gets appended to the write-ahead journal, followed by an insert into the in-memory Memtable (e.g. a skiplist). Most writes do not even trigger a disk I/O when we do not explicitly sync to disk, which is desirable to make bulk loads fast.
However, this write path is still unnecessarily slow for bulk loads. Logging to the journal, and periodically flushing memtables has a write amplification of 2* (for ascending data, we never need to compact).
If we can guarantee:
- the data is inserted in ascending order
- our tree starts out empty
we can skip the journal, flushing and compaction machinery altogether, while also needing less temporary memory.
Using a new API, we gain access directly to the internal segment writing mechanism of the LSM-tree.
This API takes a sorted iterator and creates a list of disk segments (a.k.a. SSTables), then registers them atomically into the tree.
This API is very useful for:
- schema migrations from tree A to tree B
- migrating from a different DB
- restoring data from a backup
let new_tree = ...
let stream = (0..1_000_000).map(|x| /* create KV-tuples */);
new_tree.ingest(stream.into_iter())?;
assert_eq!(new_tree.len(), 1_000_000, "bulk load was not correct");* Actually the write amp in such case is 3 currently, but that will change to be 2 in the future.
Benchmark
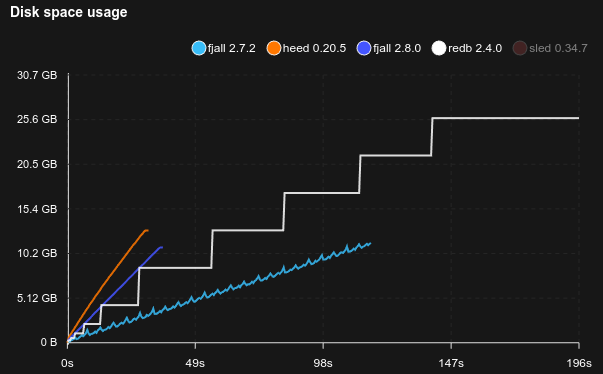
This benchmark writes 100 million monotonically ascending u128 integer keys with 100 fully random byte values:
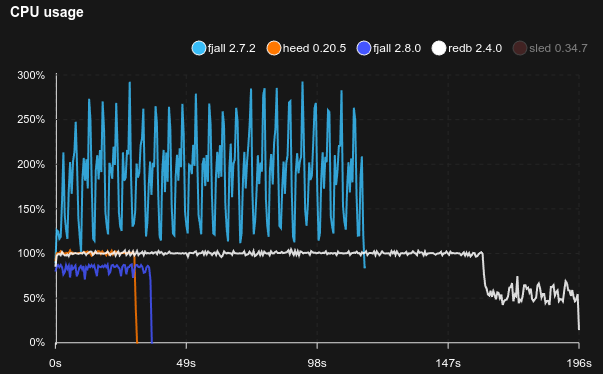
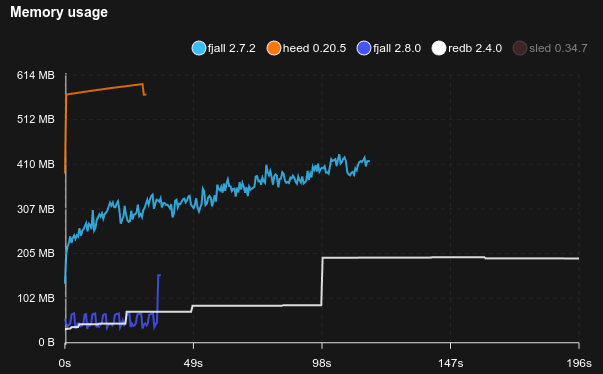
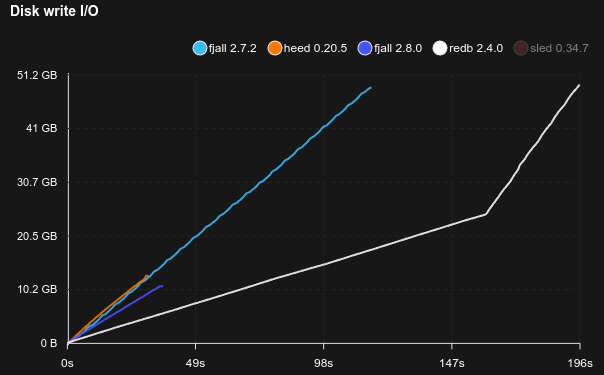
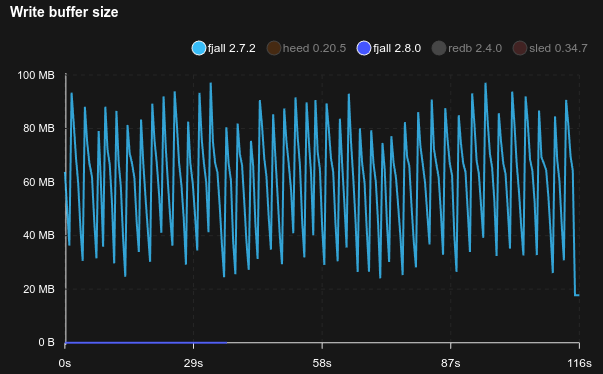
Note:
redbuses a single write transaction to load all the data, which is the fastest way to load a lot of dataheeduses a single write transaction, plus theM_APPENDput flagsleddoes not have a bulk loading mechanism, so comparing it would be unfair
Unified cache API
Setting the cache capacity has always been a bit of an awkward API. Originally it was intended to eventually allow different types of caches, however that never really materialized. Not only is the API verbose, it also makes it impossible to tune the cache capacity well in case of key-value separation.
With key-value separation, we have different types of storages: the index tree and the value log. The index tree is typically much smaller than the value log because it only stores pointers into the value log. Only small values are directly added to the index tree. Depending on the average value size, it is easily possible to have an index-to-vLog size ratio of 1:30’000 (in case all values are ~1 MB). So for 100 GB of blobs, the index tree would be ~3 MB. That makes it pretty trivial to fully cache the index tree.
However, unless perfectly knowing the size ratio and data set size, it is impossible to properly set the block cache size such that the index tree can be fully cached.
Consider the example below: we want to spend 1 GB of memory on caching, so we allow 900 MB to be used for blob caching, while reserving 100 MB for the index tree’s blocks. However, if we stored the 100 GB mentioned above, the index tree would be much smaller than our configured cache size, resulting in essentially 97 MB of wasted cache that could be used for blobs (or bloom filters) instead.
// Before (< 2.8); now deprecated
use std::sync::Arc;
use fjall::{BlobCache, BlockCache, Config};
let keyspace = Config::new(&folder)
.block_cache(Arc::new(BlockCache::with_capacity_bytes(/* 100 MB */ 100_000_000)))
.blob_cache(Arc::new(BlobCache::with_capacity_bytes(/* 900 MB */ 900_000_000)))
.open()?;
// After (2.8+)
use fjall::Config;
let keyspace = Config::new(&folder)
.cache_size(/* 1 GB */ 1_000_000_000)
.open()?;Internally, now the cache is one unified cache that stores all types of items (blocks and blobs). That way we only have to set its capacity, and let the internal caching algorithm handle what data to evict.
Replaced std::slice::partition_point
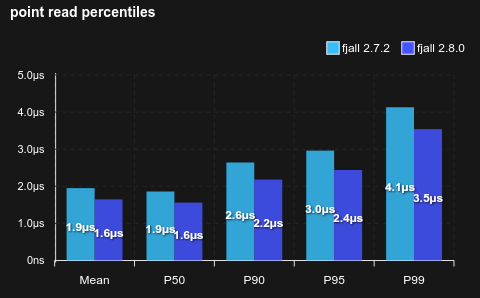
The implementation of std::slice::partition_point was modified around rustc 1.82, which caused performance regressions in binary searches.
Using a less smart, cookie cutter implementation seems to perform better for lsm-tree, restoring some read performance in cached, random key scenarios:
2.7
2.7 was mostly a maintenance update with minor uninteresting features.
Discord
Join the discord server if you want to chat about databases, Rust or whatever: https://discord.gg/HvYGp4NFFk
Interested in LSM-trees and Rust?
Check out fjall, an MIT-licensed LSM-based storage engine written in Rust.