
Everyone knows Google. For almost the entire’s internet lifetime, the Google search page has been the starting point of almost any internet user’s surfing session. To be able to serve search requests of (almost) anything that can be found on the internet, Google has to manage a huge search index. Storing a large portion of the internet requires petabytes, if not exabytes, of storage.
Bigtable
After a couple of years, the growth of Google needed a new database solution to manage its growing datasets.
The solution was Bigtable, a massively scalable database, still in use today.
Bigtable is a distributed wide-column database (somewhat exotic these days); you can think of it as a key-key-value database, where the first key maps to a row, and the second key to a column, which then contains a value, forming a 2D grid. Bigtable additionally allows versioning of any cell, forming a cube.
Ultimately, the key schema used by Bigtable is basically: <row key>.<col fam>.<col qual>.<ts>.
To insert a cell, you need to specify a row key, column key (column family + column qualifier) and a timestamp.
The column qualifier can be empty (denoted by the syntax family:).
The row key defines how the table is ordered, so it is the only indexing mechanism (there are no secondary indexes).
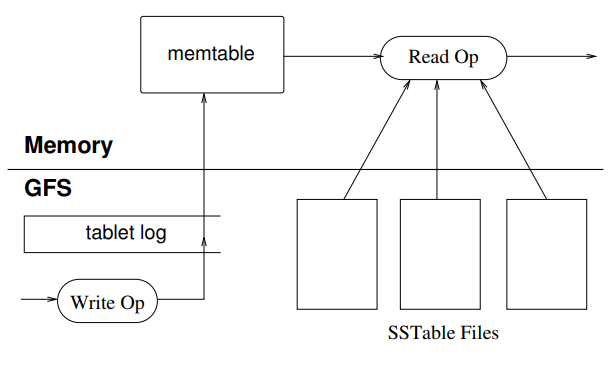
The descendants of Bigtable: LevelDB & RocksDB
LevelDB, an embeddable LSM-tree based key-value storage engine by Google, was released in 2011 and is a direct descendent of Bigtable code. It is now in maintenance-only mode.
Fun fact: Every Chromium browser ships with LevelDB.
Facebook later forked LevelDB as RocksDB, to develop it further; RocksDB is now used in countless projects.
The Webtable
To store essentially the entire internet, Google built the Webtable, a huge Bigtable table that stores HTML pages, links and some metadata of every page they crawl.
The row key of the Webtable is the URL of a page with reversed domain key, e.g. github.com/explore is converted to com.github/explore.
This maximizes locality for URLs with common domains, which we will see in action later on.
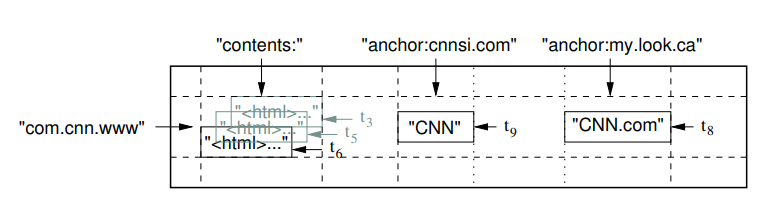
The Webtable has a pretty simple data schema:
-
The
languagecolumn family stores the Alpha-2 country code of every page. -
The
checksumcolumn family stores a checksum of the web page contents (we will use MD5). -
The
contentscolumn family stores the actual HTML document of every page. -
The
anchorcolumn family is the most interesting one. For each page A, every column inside the family is the URL of a page B that linked to page A. The cell value is the link text of the anchor (<a>) element.
Let’s recreate it in Rust
We will not build a massively scalable database or store the entire internet, but instead recreate the key-value schema used by the Webtable, and make a small scale version of it.
To keep it 100% Rust, we will use Fjall, an LSM-based key-value storage engine heavily inspired by RocksDB.
First we want to create ourselves a little wide column abstraction over our key-value store. To insert a cell, we can do something like:
// Using fjall 2.x
use fjall::Config;
type Timestamp = u64;
fn main() -> anyhow::Result<()> {
// A keyspace is one single database
let keyspace = Config::default().open()?;
// A partition is its own isolated collection/table/... (backed by an LSM-tree)
let webtable = keyspace.open_partition("webtable", Default::default())?;
// We will use \0 as delimiters
let mut wide_col_key = b"jupiter\0metrics\0mass\0".to_vec();
wide_col_key.extend((!Timestamp::default()).to_be_bytes());
// ------------------^
// store timestamp inverted, so cell versions are sorted in descending order
// insert fact about Jupiter
webtable.insert(wide_col_key, b"metric f*+!ton")?;
Ok(())
}
And to retrieve a row, we do:
// list all columns of Jupiter
for kv in webtable.prefix("jupiter\0") {
let (k, v) = kv?;
let mut splits = k.split(|&x| x == b'\0');
let row_key = std::str::from_utf8(splits.next()?)?;
let col_fam = std::str::from_utf8(splits.next()?)?;
let col_qua = std::str::from_utf8(splits.next()?)?;
let mut buf = [0; std::mem::size_of::<Timestamp>()];
buf.copy_from_slice(&k[k.len() - std::mem::size_of::<Timestamp>()..]);
let timestamp = !Timestamp::from_be_bytes(buf);
// -------------^
// We store timestamp in reverse order, so we need to un-reverse
let v = String::from_utf8_lossy(&v);
eprintln!("{row_key}@{col_fam}:{col_qua}?{ts} has value {v:?}");
}basically just splitting the compound row key back into its constituent parts, which then yields:
jupiter@metrics:mass?0 has value "metric f*+!ton"
jupiter@metrics:radius?0 has value "big"This is just some debug syntax I came up with - everything before the @ is the row key, followed by the column key (column family:qualifier), which is followed by a ? delimiter and the timestamp.
We can query just a specific column family or even a specific column by simply changing the prefix string of a prefix query:
// Filter by column family
for kv in webtable.prefix("jupiter\0metrics\0") {
// ...
}
// Get a specific column
for kv in webtable.prefix("jupiter\0metrics\0mass\0") {
// ...
}And we could even do historic queries over a specific cell, e.g. to retrieve a previous HTML version of a web page.
Creating a Wide Column module
Let’s make a nicer module to work with.
For storing a cell, we can simply provide an insert method, which will serialize the cell key using the key schema we defined:
type Timestamp = u64;
struct WideColumnTable {
#[allow(unused)]
keyspace: Keyspace,
primary: Partition,
}
impl WideColumnTable {
pub fn new(keyspace: Keyspace, name: &str) -> fjall::Result<Self> {
let primary = keyspace.open_partition(name, Default::default())?;
Ok(Self { keyspace, primary })
}
pub fn insert(
&self,
row_key: &str,
col_family: &str,
col_qual: &str,
ts: Option<Timestamp>,
value: &[u8],
) -> fjall::Result<()> {
let cell_key = serialize_cell_key(row_key, col_family, col_qual, ts);
self.primary
.insert(cell_key, value)
}
}And to get back some cells, we can create an Iterator which will deserialize key-value pairs back to a TableCell struct:
impl WideColumnTable {
// ... rest
pub fn prefix(
&self,
prefix: impl Into<fjall::Slice>,
) -> impl Iterator<Item = fjall::Result<TableCell>> {
self.primary.prefix(prefix.into()).map(|kv| {
// ignore the TableCell::new syntax, it's some nasty self_cell stuff
Ok(TableCell::new(kv?, |(k, v)| {
let mut splits = k.split(|&x| x == b'\0');
let row_key = std::str::from_utf8(splits.next()?)?;
let column_family = std::str::from_utf8(splits.next()?)?;
let column_qualifier = std::str::from_utf8(splits.next()?)?;
let ts_bytes = splits.next()?;
let mut buf = [0; std::mem::size_of::<Timestamp>()];
buf.copy_from_slice(ts_bytes);
let timestamp = !Timestamp::from_be_bytes(buf);
CellInner {
row_key,
column_family,
column_qualifier,
timestamp,
value: &v,
}
}))
})
}
}Now we have a really nice API to work with our wide-column data. Here’s the previous example with the new module:
fn main() -> anyhow::Result<()> {
let keyspace = Config::default().open()?;
let webtable = WideColumnTable::new(keyspace, "webtable")?;
webtable.insert("jupiter", "metrics", "mass", None, b"metric f*+!ton")?;
webtable.insert("jupiter", "metrics", "radius", None, b"big")?;
// None is the default timestamp = 0 -----------^
for cell in webtable.prefix("jupiter\0") {
let cell = cell?;
eprintln!("{cell:?}");
}
}Storing the page language
Now we can finally start actually modelling the Webtable.
First , let us store the simplest column family in the Webtable, language:
// It doesn't matter what order we insert in, the row key will determine the table order
webtable.insert("de.ndr", "language", "", None, b"DE")?;
webtable.insert("is.vedur", "language", "", None, b"IS")?;
webtable.insert("com.google", "language", "", None, b"EN")?;
// ... more data hereNow scanning the table, we get:
com.github@language:?0 => "EN"
com.google@language:?0 => "EN"
com.google.drive@language:?0 => "EN"
com.google.meet@language:?0 => "EN"
de.ndr@language:?0 => "DE"
is.vedur@language:?0 => "IS"You can see how - because of the reversed domain key - all Google domains live next to each other.
Storing the web page itself
Every web page is an HTML document.
This document is stored as is in the contents column family (again, no column qualifier).
We will also compute a MD5 hash and store it in the checksum column family.
let unix_timestamp = std::time::SystemTime::UNIX_EPOCH
.elapsed()
.unwrap()
.as_secs();
let html_str = "<html lang=\"is\">...";
webtable.insert(
"is.vedur",
"contents",
"",
Some(unix_timestamp),
html_str.as_bytes(),
)?;
webtable.insert(
"is.vedur",
"checksum",
"",
Some(unix_timestamp),
md5::compute(html_str).as_slice(),
)?;Now we can see how our table fills up with more columns:
// ...
is.vedur@checksum:?1741886589 => "����h�s\"H8��\u{3}PD"
is.vedur@contents:?1741886589 => "<html lang=\"is\">..."
is.vedur@language:?0 => "IS"Most column families are stored using a timestamp such that we get a history of values. This allows storing multiple versions of the same web page, and get rid of old versions lazily.
Storing the anchors
Now we have a very simple dictionary of URLs and can retrieve their language, HTML source and checksum. However, what really makes the internet work is anchors (a.k.a. links) that connect pages.
Webtable stores each anchor from page A that points to page B under the row key of page B in the anchor column family.
The column qualifier is the name of page A (the referrer).
The value is the anchor text.
So if I were to link you to Iceland’s weather service, Webtable would store that anchor as:
webtable.insert(
"is.vedur",
"anchor",
"fjall-rs.github.io/post/recreating-webtable",
None,
b"Iceland's weather service",
)?;And we can see the anchors now showing up in our scan:
is.vedur@anchor:fjall.github.io/post/recreating-webtable?0 => "Iceland's weather service"
is.vedur@checksum:?1741886589 => "����h�s\"H8��\u{3}PD"
is.vedur@contents:?1741886589 => "<html lang=\"is\">..."
is.vedur@language:?0 => "IS"This way we can easily count inbound anchors of any web page for PageRank, the very idea Google was built on.
And that’s it! We can now store pages and anchors to store data for a search engine (left as an exercise for the reader).
Creating a Webtable module
To make the API even nicer, we can further hide the WideColumnTable module behind a Webtable API, that deals with the HTML parsing (powered by visdom) etc.:
use visdom::{Vis, types::Elements};
struct Webtable {
inner: WideColumnTable,
}
impl Webtable {
fn parse_anchors<'a>(root: &Elements<'a>) -> Elements<'a> {
let anchors = root.find("a");
anchors
}
pub fn iter_anchors_to_page(
&self,
rev_domain: &str,
) -> impl Iterator<Item = fjall::Result<Cell>> {
let prefix = format!("{rev_domain}\0anchor\0");
self.inner.prefix(prefix)
}
pub fn insert(&self, url: &str, html: &str) -> fjall::Result<()> {
let rev_url = reverse_domain_key(url.trim_start_matches("https://"));
let unix_timestamp = std::time::SystemTime::UNIX_EPOCH
.elapsed()
.unwrap()
.as_secs();
let Ok(root) = Vis::load(html) else {
return Ok(());
};
if let Some(lang) = root.find("html").attr("lang") {
let lang = lang.to_string();
self.inner
.insert(&rev_url, "language", "", None, lang.as_bytes())?;
}
self.inner.insert(
&rev_url,
"contents",
"",
Some(unix_timestamp),
html.as_bytes(),
)?;
self.inner.insert(
&rev_url,
"checksum",
"",
Some(unix_timestamp),
md5::compute(&html).as_slice(),
)?;
// To get the list of anchors, we will need to parse out all anchors out of the HTML document
for anchor in Self::parse_anchors(&root) {
let Some(href) = anchor.get_attribute("href") else {
continue;
};
let href = href.to_string();
if href.starts_with("mailto:")
// ... filter out some stuff ...
{
continue;
}
// imagine some string magic here
let href = normalize_href(href);
self.inner.insert(
&href,
"anchor",
url,
Some(unix_timestamp),
anchor.text().as_bytes(),
)?;
}
Ok(())
}
}Scraping some pages
And now we can easily download some pages (using some HTTP client, reqwest in this case) and store it:
let test_urls = ["https://vedur.is", "https://news.ycombinator.com"];
for url in test_urls {
eprintln!("Scraping {url:?}");
let res = reqwest::blocking::get(url)?;
if res.status().is_success() {
let html = res.text()?;
webtable.insert(url, &html)?;
}
}If we now look at the database, we can see - after scraping the Hacker News front page - a new anchor (amongst others):
org.duckdb@anchor:https://news.ycombinator.com?1741886589 => "The DuckDB Local UI"
// ... restWhich basically means: duckdb.org was linked to by news.ycombinator.com using the text "The DuckDB Local UI".
With the iter_anchors_to_page method, we can scan over the anchors that point to a web page:
for cell in webtable.iter_anchors_to_page("org.duckdb") {
let cell = cell?;
eprintln!("{cell:?}");
}which will give the same anchor as above (but not others).
Locality groups
The current data schema can run into a problem though: if we wanted to aggregate how many web pages exist per language, we would have to scan the entire table, including all HTML documents. That would be prohibitely slow.
Bigtable has a feature called “locality groups”, that allows grouping certain column families together, which allows data partitioning:
Segregating column families that are not typically accessed together into separate locality groups enables more efficient reads.
For example, page metadata in Webtable (such as language and checksums) can be in one locality group, and the contents of the page can be in a different group: an application that wants to read the metadata does not need to read through all of the page contents.
To do that, we can simply write the column families we want into a new WideColumnTable, which will internally create a new LSM-tree:
struct Webtable {
#[allow(unused)]
keyspace: Keyspace,
inner: WideColumnTable,
lg_meta: WideColumnTable,
lg_contents: WideColumnTable,
}
impl Webtable {
pub fn new(keyspace: Keyspace) -> fjall::Result<Self> {
// this is where all column families land that are not part of any locality group
let inner = WideColumnTable::new(keyspace.clone(), "webtable")?;
// write metadata (checksum and language) into this locality group
let lg_meta = WideColumnTable::new(keyspace.clone(), "lg_meta")?;
// write HTML contents into this locality group
let lg_contents = WideColumnTable::new(keyspace.clone(), "lg_contents")?;
Ok(Self {
keyspace,
inner,
lg_meta,
lg_contents,
})
}
pub fn iter_metadata(&self) -> impl Iterator<Item = fjall::Result<Cell>> {
self.lg_meta.prefix("")
}
// ... rest
}If we now scan over our metadata locality group, we only get the checksum and language of all the pages.
The end
And now we finally have a Rust-only, embedded toy Webtable, the central part of the original Google search engine.
To make a fully featured search engine, you would need way more components, including a search index and crawlers; see the original Google paper for more information about that.
Source code can be found here.
Discord
Join the discord server if you want to chat about databases, Rust or whatever: https://discord.gg/HvYGp4NFFk
Interested in LSM-trees and Rust?
Check out fjall, an MIT-licensed LSM-based storage engine written in Rust.