
Release 2.1 is devoid of any new features, but features some performance optimizations in three areas.
Hashing in read hot path
lsm-tree uses quick_cache to cache index and data blocks.
The cache keys are very short tuples of u64s:
type SegmentId = u64;
type TreeId = u64;
type BlockOffset = u64;
struct GlobalSegmentId(TreeId, SegmentId);
struct CacheKey(GlobalSegmentId, BlockOffset);Storing the tree ID allows sharing the block cache across multiple LSM-trees, without having to be concerned about accidental collisions.
The same schema is used in value-log to cache blobs (large values).
The hashing function used should be as fast as possible for this specific purpose (hashing three u64s).
quick_cache uses ahash by default, but can be configured with other hashers.
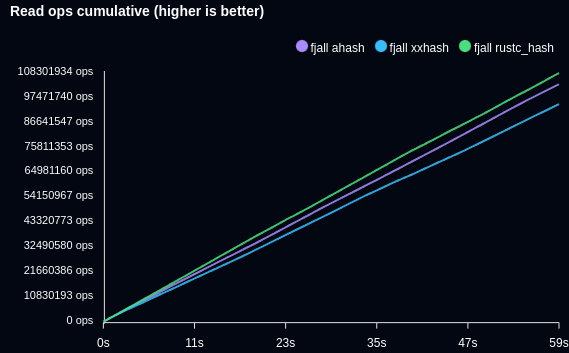
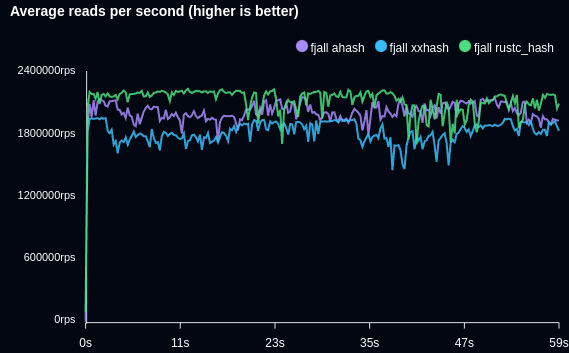
lsm-tree and value-log 2.0.0 used xxhash::xxh3, but benchmarking found that ahash and rustc_hash perform better here.
Ultimately, rustc_hash won, shaving off about 25ns compared to xxhash.
For a fully cached workload, this can result in tens of thousands more point reads per seconds. The following benchmark writes 100’000 items and retrieves a random (Zipfian distribution) item in a hot loop, with the entire data set fitting into memory:
Less cloning in segment writer
When writing disk segments, the first and last key are stored in the segment metadata. This allows range culling when performing range reads. We do not know which, and how many, items are written into a segment, as the input is an iterator of KV-tuples. This makes the first key easy to determine:
struct Writer {
buffer: Vec<Kv>,
first_key: Option<Key>,
last_key: Option<Key>,
}
impl Writer {
pub fn write(&mut self, kv: Kv) {
if self.first_key.is_none() {
self.first_key = Some(kv.key.clone());
}
// Old implementation, ouch!
self.last_key = Some(kv.key.clone());
self.buffer.push(kv);
if self.is_buffer_full() {
self.spill_buffer();
}
}
fn spill_buffer(&mut self) {
// Omitted: Create block and write to file
// ...
self.buffer.clear();
}
pub fn finish(self) -> Metadata {
if !self.buffer.is_empty() {
self.spill_buffer();
}
self.create_metadata()
}
}Until now, the last key field was always set. We know the iterator is sorted in ascending order, so an incoming key may always be the last one. After all, we don’t know when the iterator is done. This cause a lot of unnecessary Arc clones for any flush or compaction operation (one for each KV tuple).
We do know that because the iterator is sorted, the blocks will be sorted, too. KV-tuples are grouped into blocks using the writer’s buffer. So the last key of the last block must be the last key of the entire iterator:
impl Writer {
pub fn write(&mut self, kv: Kv) {
if self.first_key.is_none() {
self.first_key = Some(kv.key.clone());
}
self.buffer.push(kv);
if self.is_buffer_full() {
self.spill_buffer();
}
}
fn spill_buffer(&mut self) {
// ...
self.last_key = Some(self.buffer.pop().key);
self.buffer.clear();
}
pub fn finish(self) -> Metadata {
// ...
}
}Now, only the last key of each block is used to set writer.last_key.
And in fact, it does not even need to be cloned, because we can just take ownership of the buffer’s last item.
Flushing 1 million items with a 16-byte key and empty value takes about 370ms (all features disabled).
With the above changes, it takes about 355ms, so a ~4% increase in performance.
Faster range culling
When querying a range, all candidate segments that overlap the range are collected. Disjoint levels in Leveled trees can grow quite large (L3 by default has a max size of 512 segments).

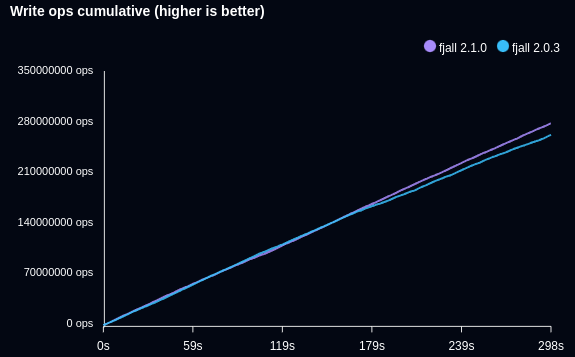
The range culling function filtered linearly, which caused range queries in large trees to perform suboptimally.
Luckily, disjoint levels are sorted by key range, meaning we can binary search inside the level.

This reduces “key range contains” operations inside a level to O(log n) - so ~500 comparisons less for a level with 512 segments.
The following benchmark writes an ever increasing data set of timeseries data points, and retrieves the latest 100 entries:
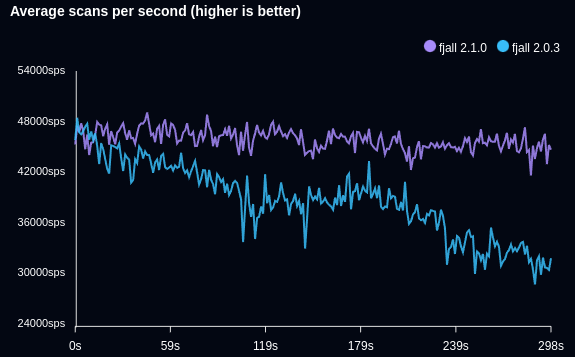
Notes:
- Fjall has been purposefully tuned to cause performance degradation faster to demonstrate the issue (by reducing the memtable size to 1/2 the default)
Reducing large range scan initialization costs
When setting up a range read, each segment that is not filtered by the algorithm above, is collected.
This causes unnecessarily many Arc clones. Large or (partially) open ranges can have thousands of segments, resulting in microseconds of time spent in this stage.
Also each segment was immediately converted into a SegmentReader, which is cheap, but not for thousands of segments!
For large trees, this can make operations such as first_key_value or last_key_value too slow.
Again, the responsible code in question has O(n) complexity.
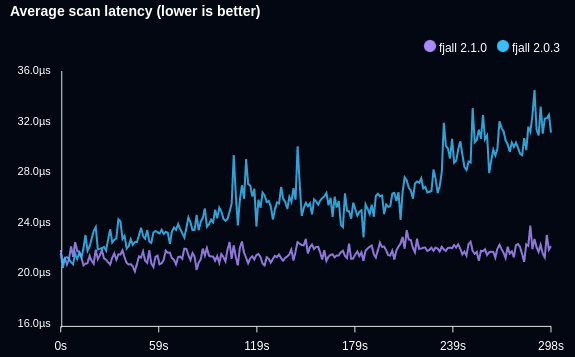
To reduce Arc clones, we need to be able to clone an entire Level in O(1) time. To do so, levels are now themselves wrapped in an Arc. A level is now immutable; changes in the level structure are instead performed using copy-on-write. This way, no matter how large the level, we only perform a single Arc clone, so 6 Arc clones for an entire tree’s disjoint levels, making the cloning stage run in constant time.
(For non-disjoint levels, each non-filtered segment is still collected as before. This only happens in L0, or in size-tiered trees, so this is fine.)
To be able to iterate through a cloned level, a new LevelReader struct was introduced.
This struct can read through a disjoint level of segments, by keeping track of the segments it is reading, has read and may consider to read using two pointers (lo and hi).
When a segment is fully read, the next segment reader is initialized.
This way, we only lazily initialize segment readers, and do not have increasing cloning costs when setting up range reads in an ever increasing tree.

The following benchmark writes timeseries data and retrieves the latest data point (Db::last):
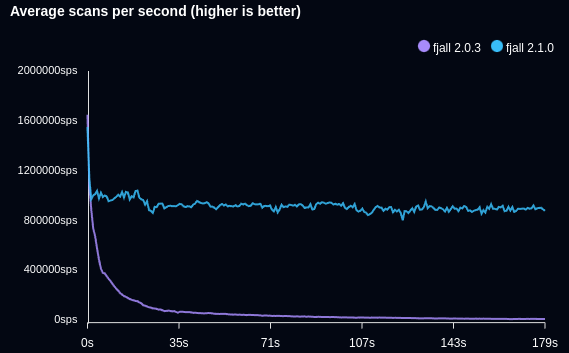
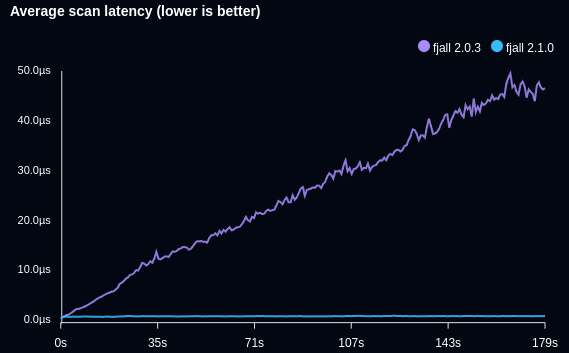
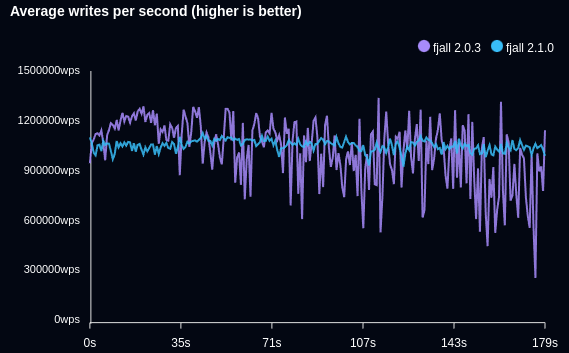
Fjall 2.1
lsm-tree and fjall 2.1 are now available in all cargo registries near you.
* Testing rig for all benchmarks: i9 11900k, Samsung PM9A3 960 GB
Discord
Join the discord server if you want to chat about databases, Rust or whatever: https://discord.gg/HvYGp4NFFk
Interested in LSM-trees and Rust?
Check out fjall, an MIT-licensed LSM-based storage engine written in Rust.