
Fjall is an embeddable LSM-based forbid-unsafe Rust key-value storage engine. Its goal is to be a reliable & predictable but performant general-purpose KV storage engine.
Like 2.1, the 2.3 release is another one focused on maintenance and performance improvements, most of them in the lsm-tree crate.
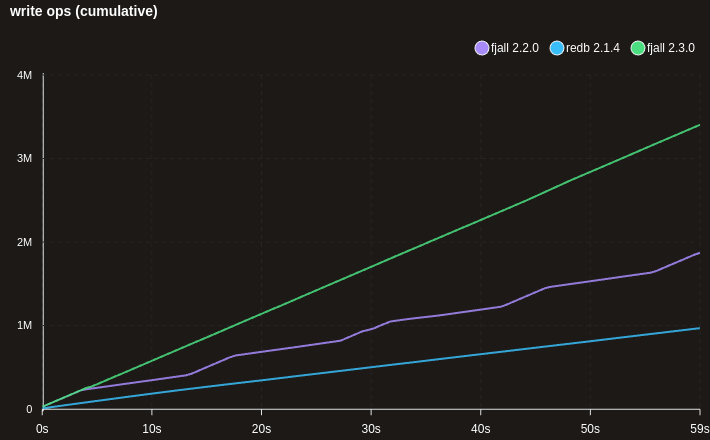
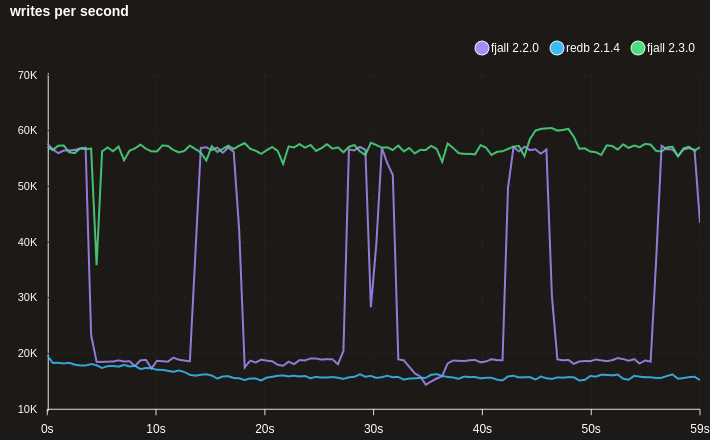
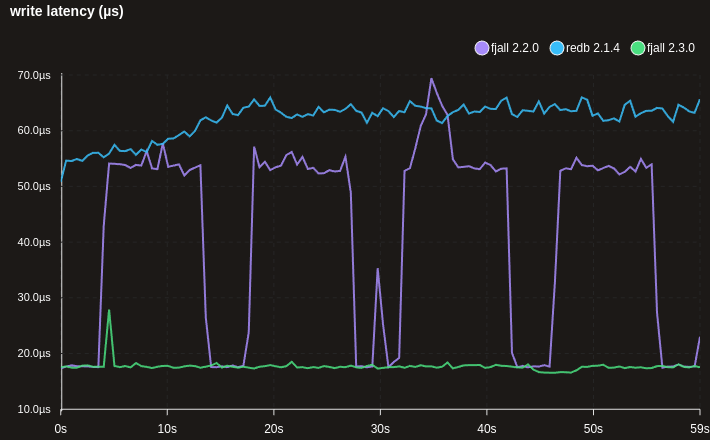
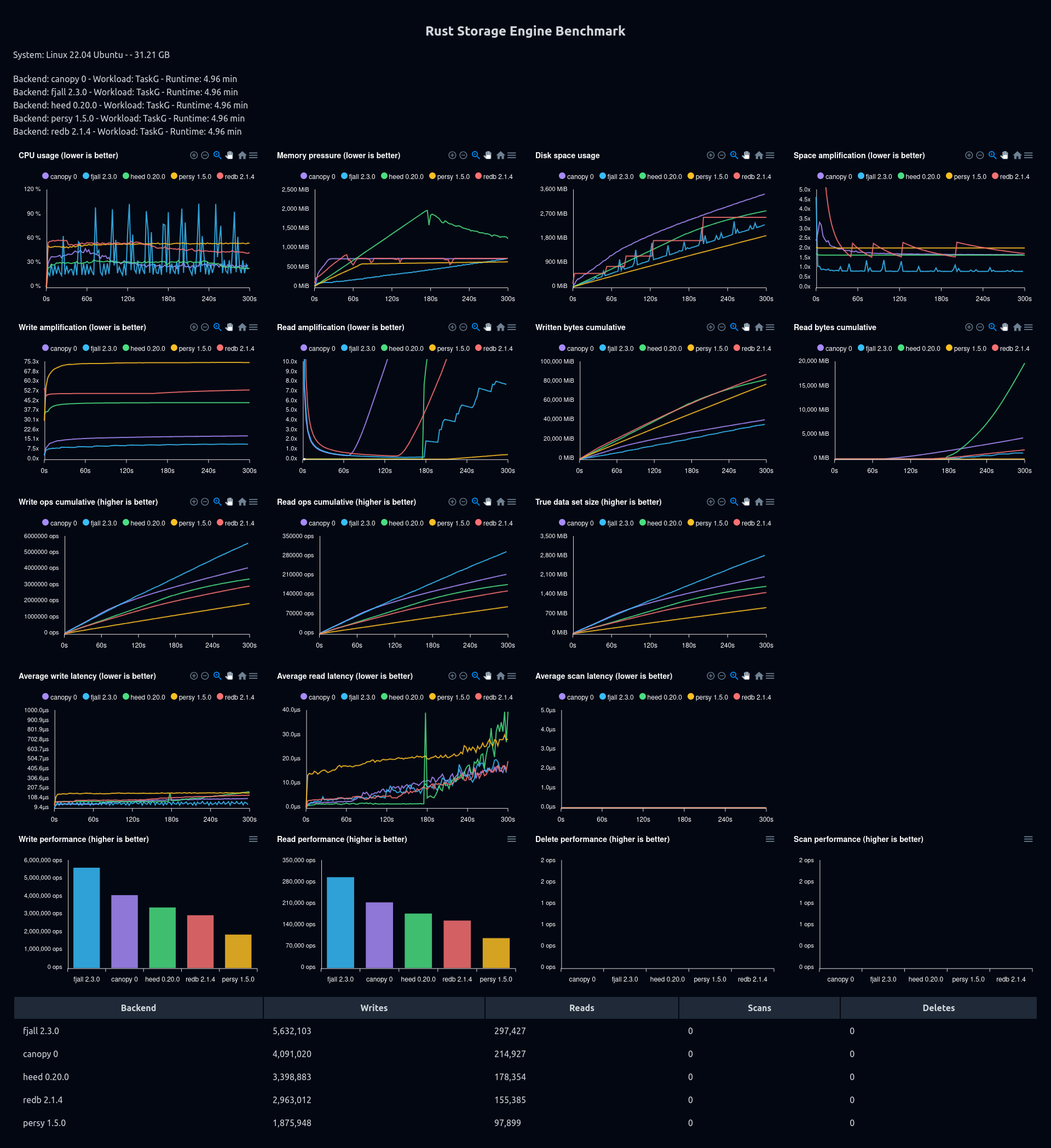
Better write scaling of random key insertions
In a leveled LSM-tree, when a level A exceeds its target size, some segments of it are merged into the next level A+1, by rewriting all overlapping segments in level A+1.

The function that picked the segments to compact in level A was very naive stupid, and caused one side of the keyspace (lower keys) to be preferred.
This caused the segments in level A+1 to be very granular for a small key range.
Future compactions would then have to rewrite an increasing amount of segments, causing longer compaction runs, up until the system write stalled, essentially strangling itself.

The function has been improved to take into account all possible windows of segments that could be compacted, and choose the least-effort set with the most payoff.
This results in much more sane write scaling for huge data sets that are writing random keys (e.g. UUIDs) - 100M x 100 bytes here:
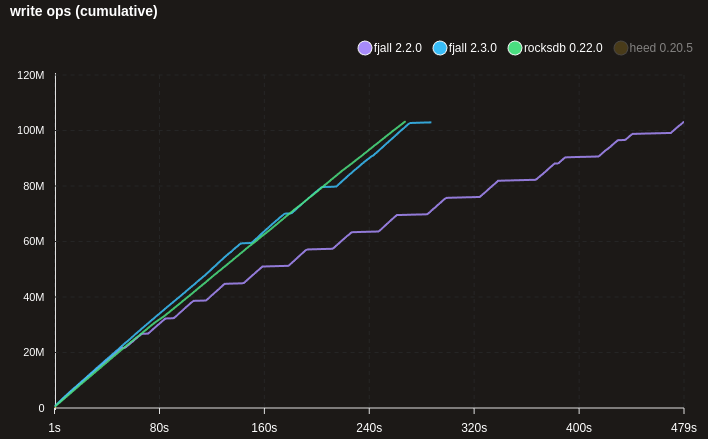
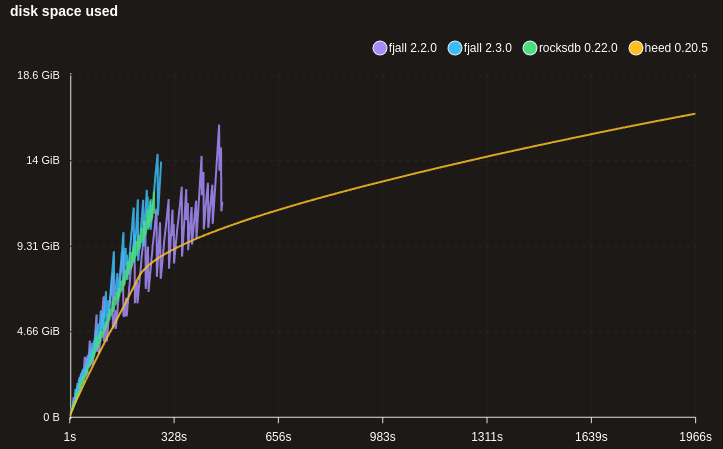
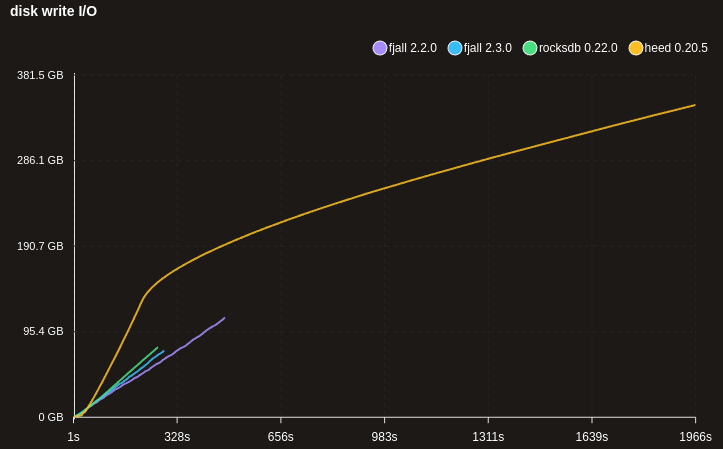
Note: the MDB_NO_SYNC flag was used for heed, which may not be safe to use, but not using it makes writes way too slow.
Faster LZ4 (de)compression
By default, lsm-tree uses the lz4_flex crate for compression.
The crate has a (default) safe and (faster) unsafe mode.
Up until now, the safe mode was used.
But seeing the crate being used in unsafe mode in tantivy (and thus quickwit) gave me the confidence to change it to unsafe mode as well in lsm-tree.
The change results in slightly faster compaction; micro benchmarks showed a ~5-15% decrease in decompression times.
Fixed degradation in point reads in some workloads
Under certain conditions, point reads to old KVs in certain workloads could, at some point, hit a performance cliff. This was caused by a control flow mishap, causing unnecessary lookups in levels that did not contain the requested key.
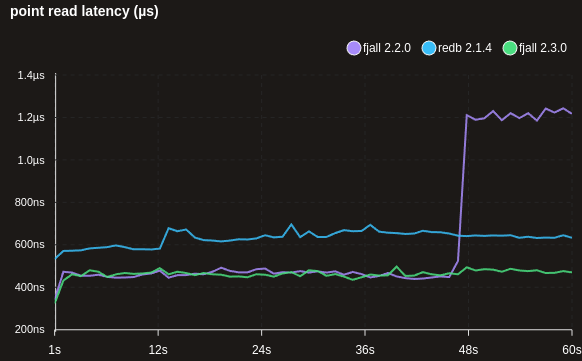
Faster sync writes
To reduce fsync latency, the journal file is preallocated to 16 MiB. However, for small values, the default memtable size, combined with the overhead of journal entries, would cross that threshold. This would result in sync writes flip flopping between fast and moderate, which is not desirable.
The default journal preallocation has been increased to 32 MiB, which seems to be a good default for a variety of value sizes.
In the future, the preallocation size will be made configurable, and should be set to around the largest expected memtable size.
Disk used: Samsung PM9A3
Decreased memory usage in monotonic workloads
LSM-trees use probabilistic filters (e.g. Bloom filters) to skip superfluous I/O operations when traversing through levels. Because generally 90% of data is kept in the last level, many keys will not be present in the upper (smaller) levels, so skipping I/O work there (especially L0) is very important.
Because the upper levels are very small and short-lived, the bloom filter FPR can be set abnormally low at very low costs.
However, when the segments are never rewritten (e.g. time series), but instead moved down (”trivial move”), the bloom filter memory overhead will end up being unexpectedly high (1.5 - 2.5x).
The compaction has been tweaked to force rewriting segments when they are demoted into the deeper, “colder” levels (L2+). This will probably be tweaked in the future to make it less aggressive for certain workloads.
The following benchmark writes ~250M time series data points:
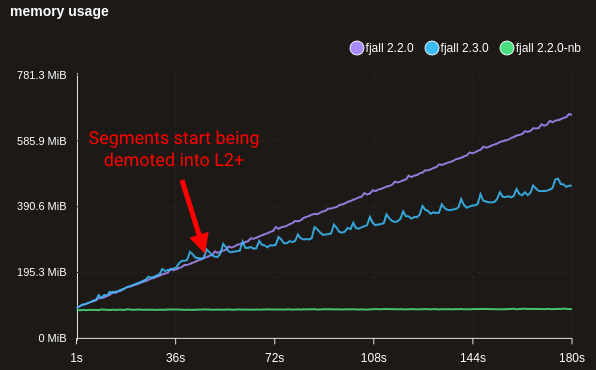
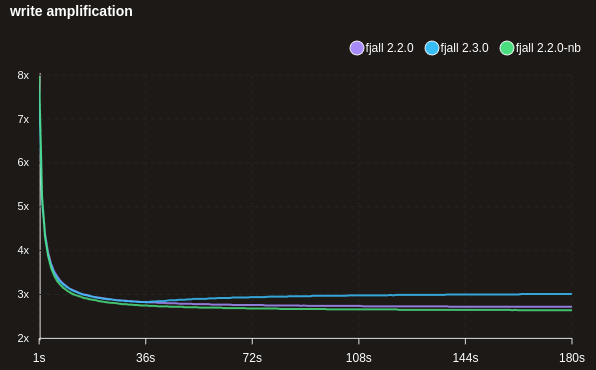
This increases background I/O costs; notice how the write amplification changes from ~2 to ~3, as we now write each item three times (WAL, flush, L1→L2 compaction) instead of twice. However, write throughput stays more or less the same.
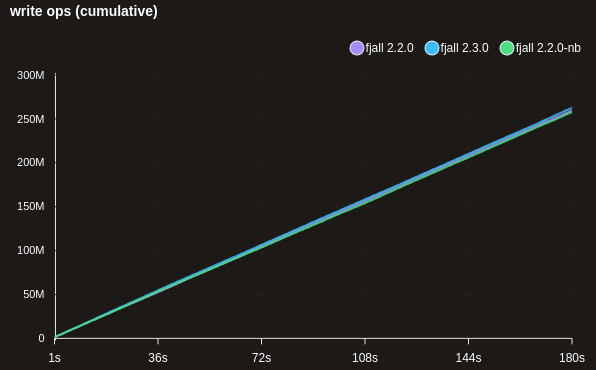
Note: fjall 2.2.0-nb disabled bloom filters altogether
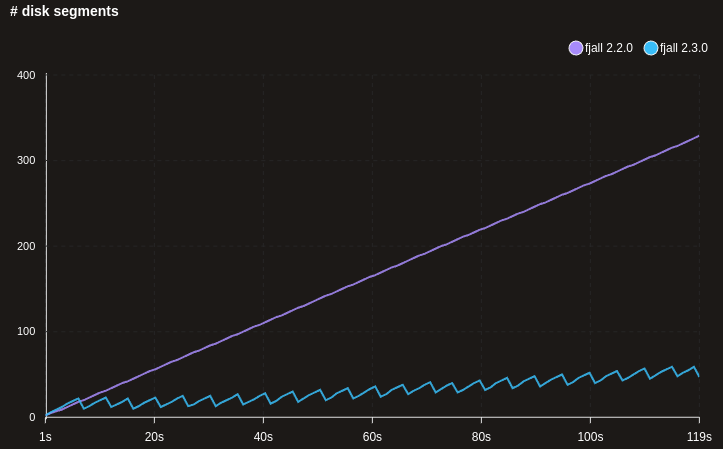
Additionally, when segments are very small, they will instead be tried to be merged together to reach the configured segment target size (64 MB by default).
Additional benchmarks
I reran the benchmarks from CanopyDB with an extended period of 5 minutes, to better demonstrate the scaling of the storage engines.
Test rig: i9 11900K, 32 GB RAM (limited to 2 GB using systemd), Samsung PM9A3.
Note that cumulative stats are kind of misleading right now, they will be fixed in an upcoming version of the benchmark tool.
50% reads, 20% scans, 10% overwrites and 20% inserts (random)
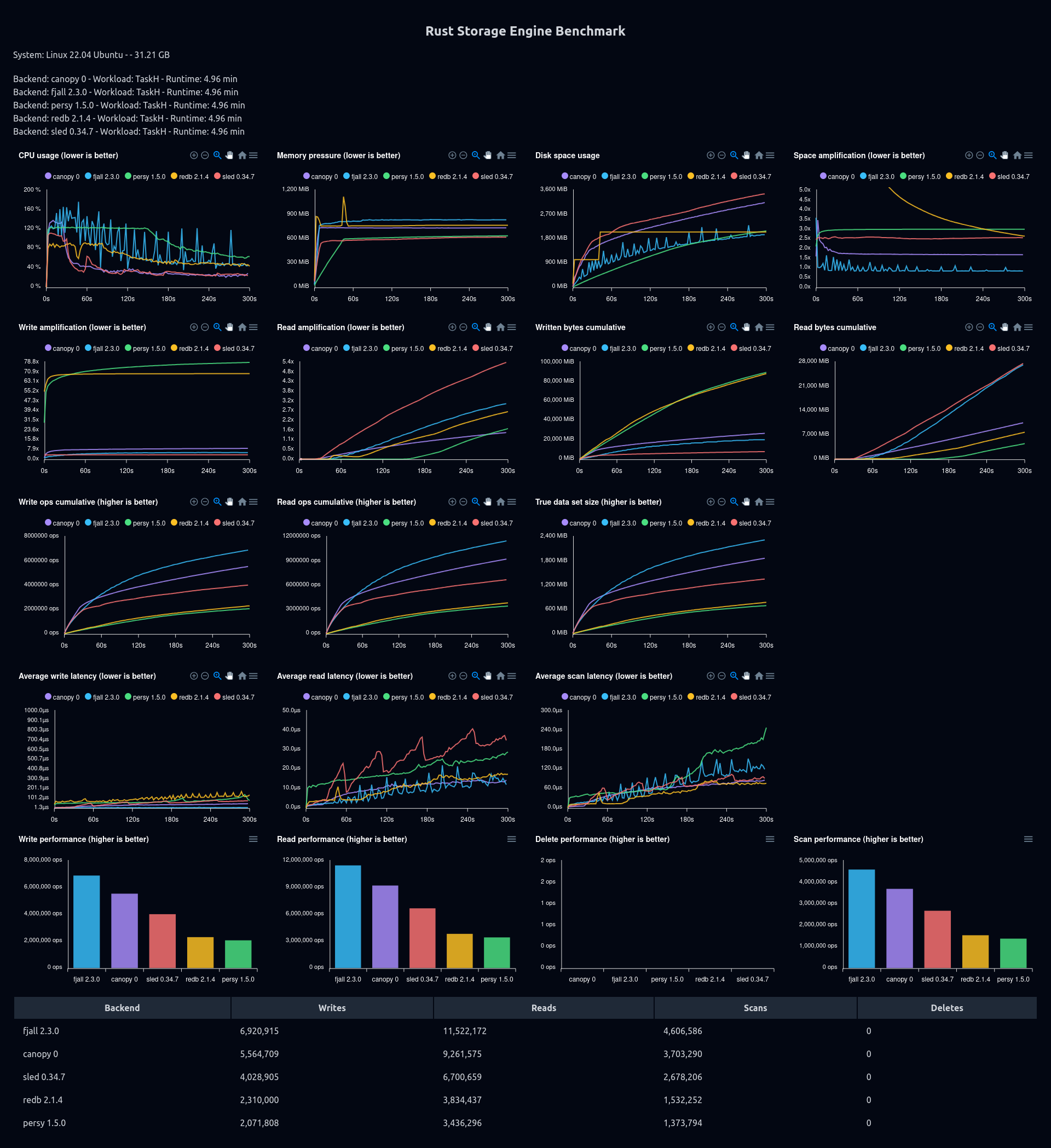
50% reads, 20% scans, 10% overwrites, and 20% inserts (sequential)
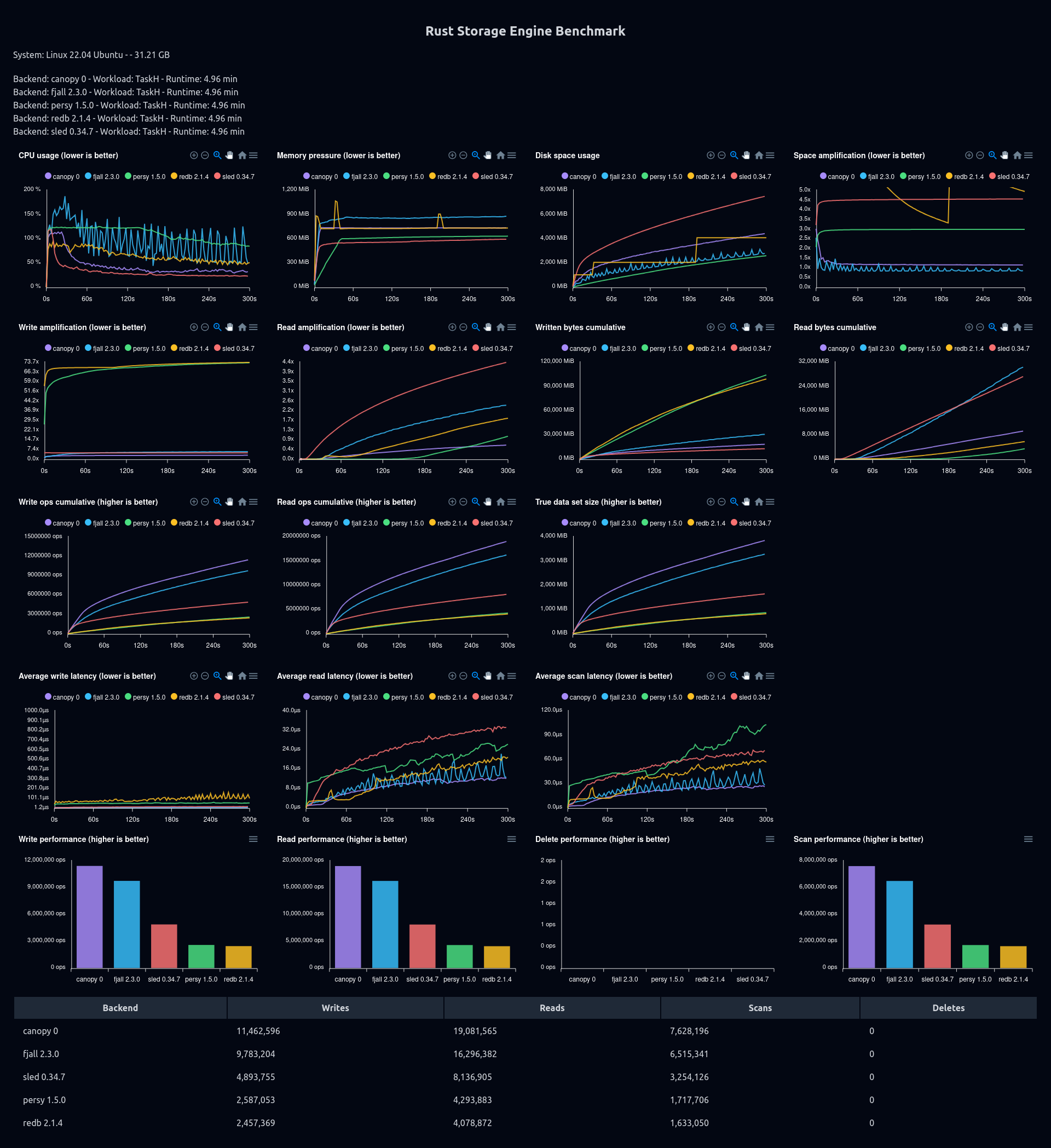
(preloaded) 50% reads, 20% scans, 10% overwrites, and 20% inserts
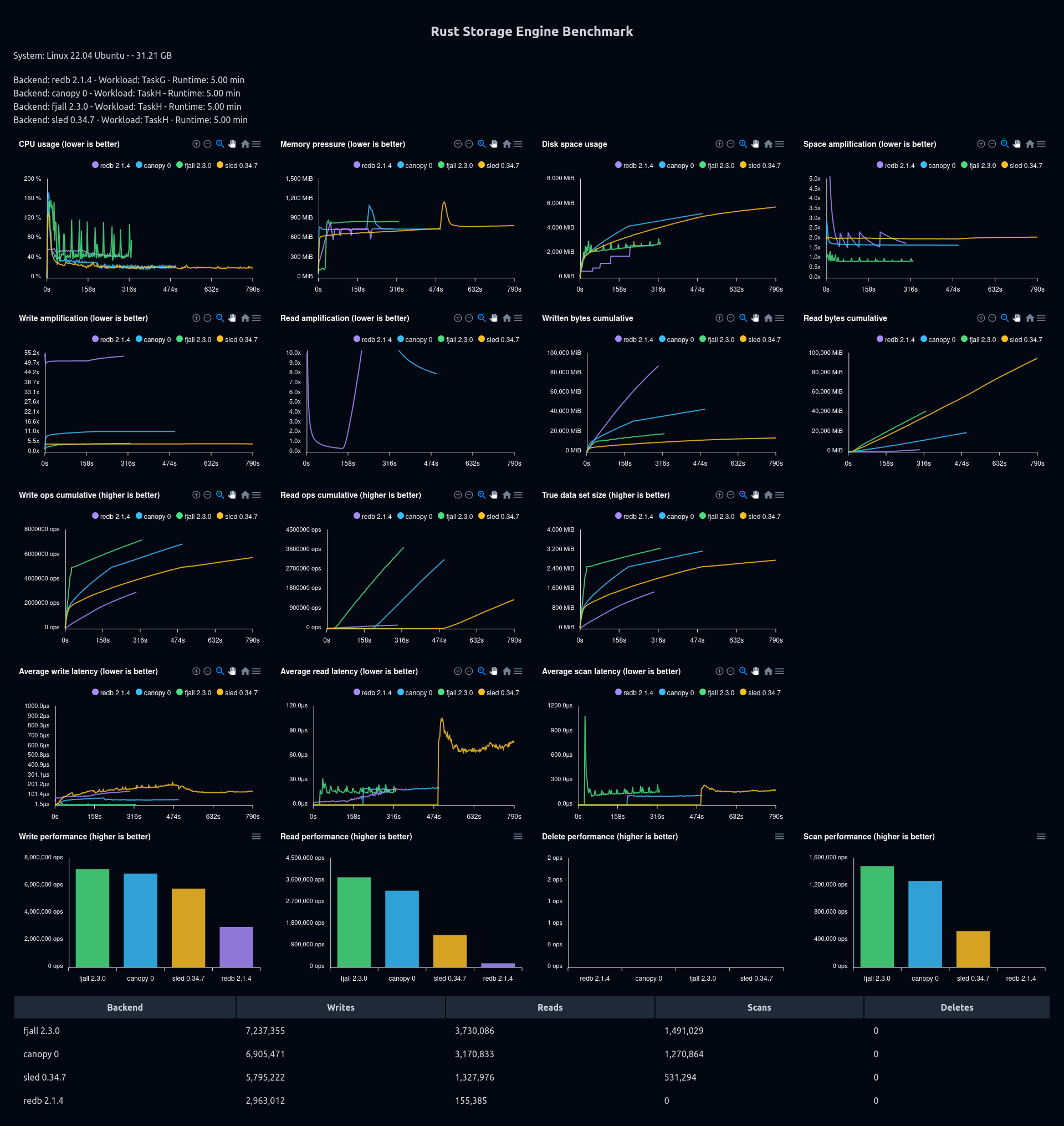
(preloaded, 20 KB values) 50% reads, 20% scans, 10% overwrites, and 20% inserts
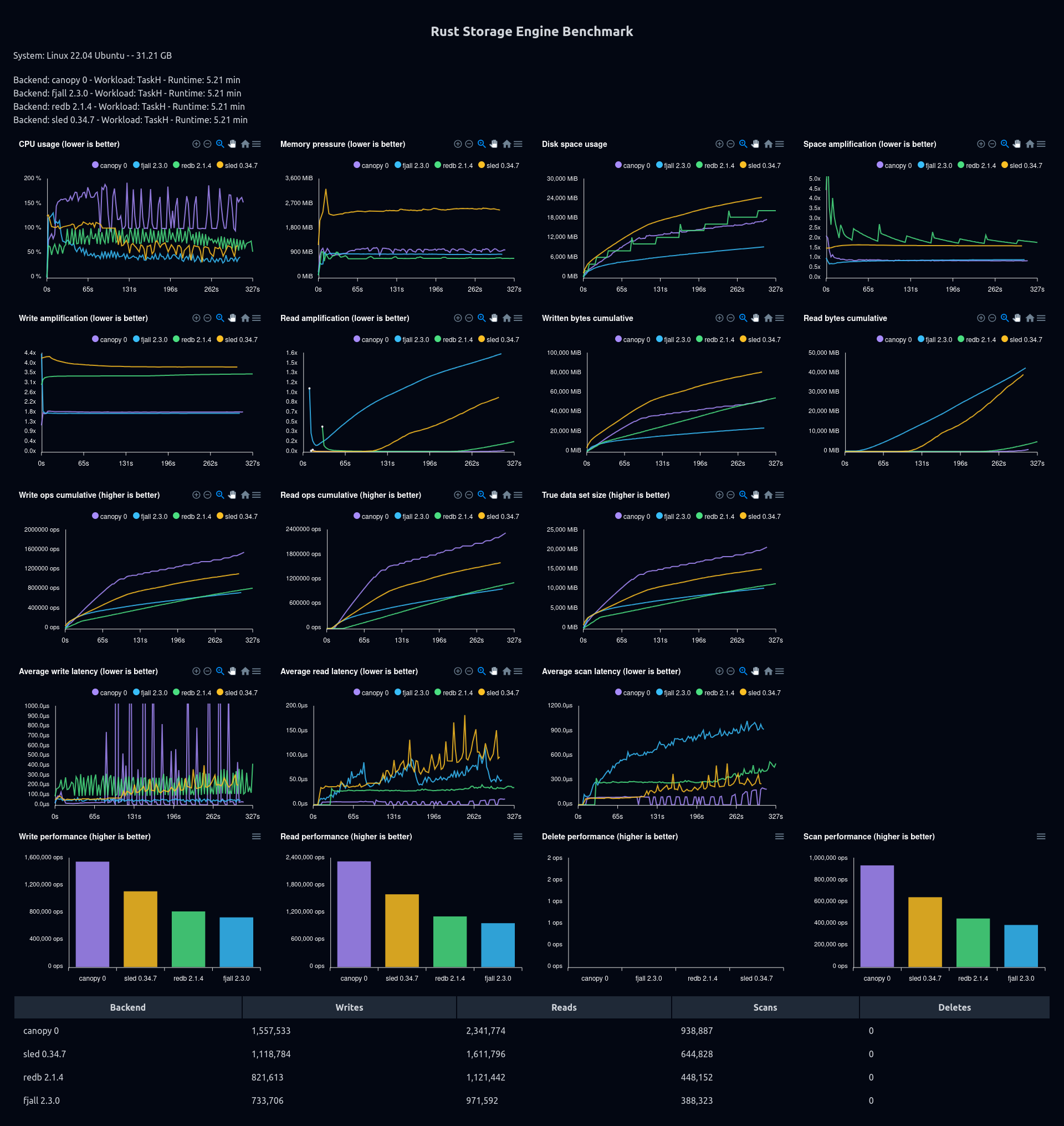
95% inserts, 5% reads (sync commit)
Discord
Join the discord server if you want to chat about databases, Rust or whatever: https://discord.gg/HvYGp4NFFk
Interested in LSM-trees and Rust?
Check out fjall, an MIT-licensed LSM-based storage engine written in Rust.
