
As teased in the 2.0 announcement, the newly introduced Slice type allowed changing the underlying implementation without breaking changes.
Until now, an Arc<[u8]> was used.
The 2.6 release now introduces a new underlying byte slice type to optimize memory usage and deserialization speed.
Arc basics
Arc<T> (Atomically Reference Counted) is a smart pointer in the Rust standard library that can be shared between threads.
Its contents (the generic parameter T) are allocated on the heap, including some atomic counters (called the strong and weak count) that defines how often the value is currently referenced.
Whenever an Arc is cloned, the strong count is incremented by 1, using atomic CPU instructions.
When an Arc is dropped, the strong count is decremented by 1.
Because an atomic fetch-and-subtract operation returns the previous value, one - and only one - dropped Arc will be the “last owner”, making sure it will free the heap-allocated memory.

Arcs are a simple way to share some data across your application, no matter how many threads there are. However, there are a couple of caveats:
- the Arc’s contents (the
T) are read-only, unless you can guarantee you are the sole owner (usingArc::get_mutor synchronization such as a Mutex) - each newly constructed Arc has additional memory overhead because of its additional reference counts (strong and weak)
- sharing Arcs (by “cloning”) is more expensive than a reference because of the atomic CPU instruction(s) used
Arc’d slices
Things get a bit more complicated when you want to store a slice of values ([T]) inside an Arc.
Now, we also have to keep track of the slice’s length.
This is done using a “fat” pointer.

When constructing an Arc’d slice, there is no proper API for that, one easy way is to use an intermediary Vec:
let v = vec![0; len]; // heap allocation
let a: Arc<[u8]> = v.into(); // heap allocationUnfortunately, this requires 2 heap allocations.
When storing a slice, an Arc has a stack size of 16 bytes (fat pointer), plus 16 bytes for the strong and weak counts, giving us a memory overhead of 32 bytes per value.
Usage of Arc<[u8]> inside lsm-tree
lsm-tree, by default, represents keys and values using an Arc<[u8]>, in a newtype called Slice.
One interesting property is that LSM-trees are an append-only data structure - so we never need to update a value, meaning all Slices are immutable.
struct Slice(Arc<[u8]>);
// ----------^
// the Slice is opaque, the user does not know it uses an Arc internallylsm-tree already supports bytes as an underlying Slice implementation since version 2.4.0.
However, while flexible, bytes is not a silver bullet, and using it as the default would include another required dependency.
So for the default implementation, replacing Arc could be beneficial as it has some downsides:
Downside: Deserialization into Arc<[T]>
When deserializing a data block from an I/O reader, each key and value is constructed, using something like this:
let len = read_len(file_reader)?; // values are prefixed by length
let v = vec![0; len]; // heap allocation
v.read_exact(file_reader)?;
let v = Slice::from(v); // construct Arc<[u8]> from vector; heap allocation againIn this scenario, we want fast deserialization speed, so skipping the second heap allocation would be beneficial.
Downside: Weak count
Next to the strong count there is also a weak count.
However this weak count is never used.
Because each key and value is an Arc<[u8]>, each cached key and value carries an (unused) weak count.
Omitting the weak count would save 8 bytes per Slice.
Downside: Empty slices allocate
When using Arc<[T]>, empty slices still need a heap allocation:
for _ in 0..1_000 {
let a = std::sync::Arc::<[u8]>::from([]);
}If you run this example, it will perform 1’000 heap allocations, even though the slice is empty. While empty slices are not commonly used, they can still play a pivotal role in certain situations:
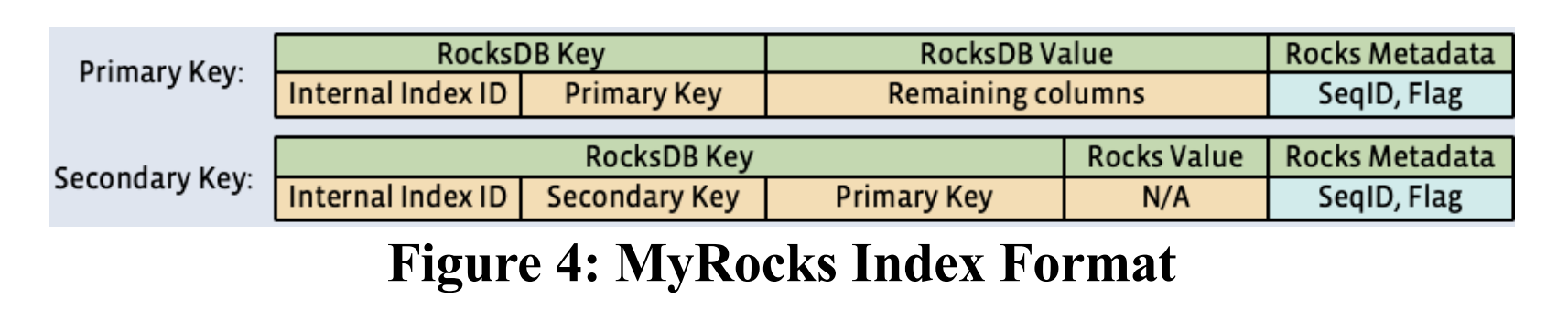
As shown in MyRocks’ key schema, every secondary index entry is just an encoded key, with no value (“N/A”). Here, not needing a heap allocation for the empty value would be very beneficial.
Consideration: Large strings have no real life use
The len field takes 8 bytes, so it can represent every possible string.
However, large byte slices simply do not exist in real world KV scenarios (lsm-tree supports 32-bits of length, though I would not recommend anything above ~1 MB).
Reducing it to 4 bytes still allows slices of up to 4GB, saving another 4 bytes per slice.
Introducing byteview
byteview is a new Rust crate that implements a thin, immutable, clonable byte slice.
It is based on Umbra/CedarDB’s “German-style” strings (also found in projects like Polars, Apache Arrow and Meta’s Velox).
However, byteview uses some additional meta data to support a slice-copy operation like Tokio’s bytes crate.
For small values there can be some big space savings:

How byteview works

The basic concept of byteview is pretty simple.
The struct size is fixed at 24 bytes.
The length is stored as 4 bytes at the very start.
If the string is 20 bytes or shorter, it is directly inlined into the string, no pointer or heap allocation needed.
In this case, the memory overhead is (20 - n + 4) bytes.
Indeed, byteview allows inlined strings up to 20 bytes (instead of 12 as is typical with other implementations); the struct is larger because of its additional pointer.
Luckily, 16 byte strings tend to be pretty common, because that is the size of all common UUID-like string schemas, bringing quite significant space savings there (as seen above).
If the string is larger than 20 bytes, it will be heap allocated and the pointer + length stored in the struct.
The remaining 4 bytes store the first four bytes (prefix) of the string, allowing short-circuiting some eq and cmp operations without pointer dereference.
The heap allocation contains a single strong count and the byte slice.
In this case, the memory overhead is 32 bytes.
Results
Block deserialization speed benchmark
byteview natively supports deserialization from any io::Read without intermediate buffer for construction:
let len = read_len(file_reader)?; // values are prefixed by length
let v = ByteView::from_reader(file_reader, len); // (possibly) heap allocation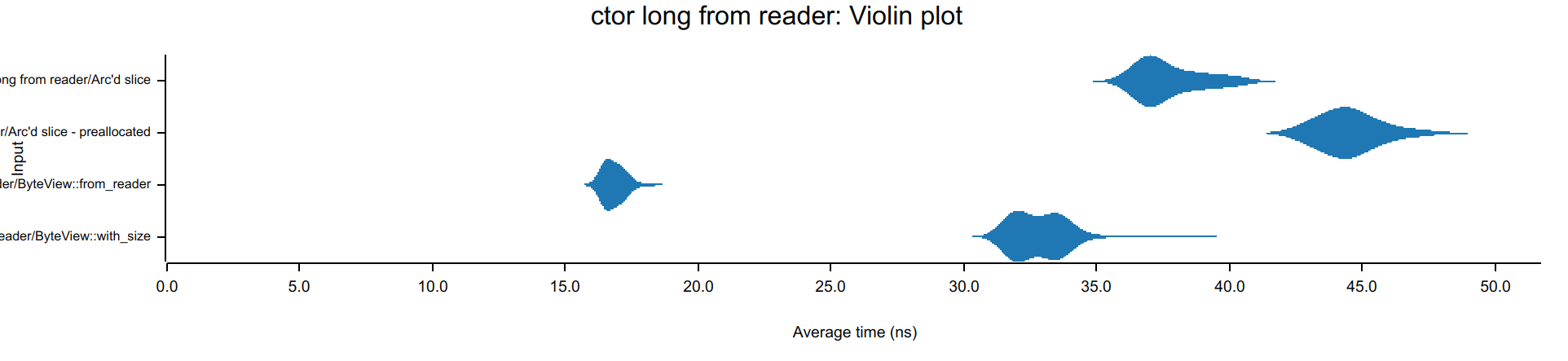
For inlinable values, there is no heap allocation:
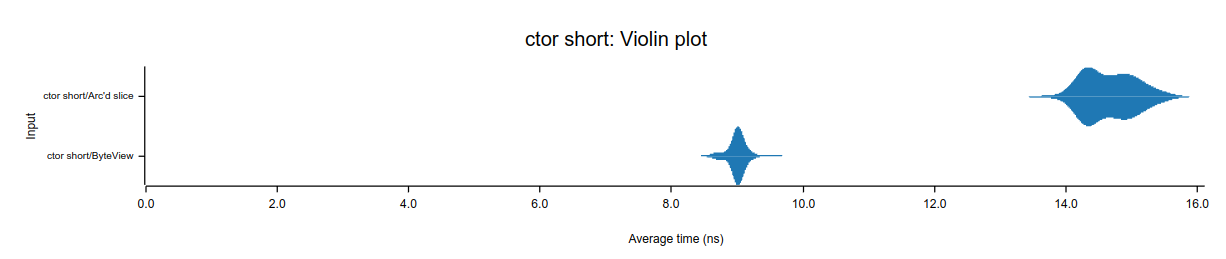
Reading large blobs
In a key-value separated LSM-tree, the user value is not stored as-is, but prefixed by some additional metadata.
Because we cannot return that metadata to the user, previously lsm-tree had to clone out the user value into a new Slice.
For large blobs, this would cause one additional heap allocation per blob read, and an O(n) memcpy for each value.
Because all inserts are initially added to the memtable as an inlined value, fresh inserts also needed to be cloned when read.
byteview supports slicing an existing heap allocation, so we can skip the heap allocation and copying, giving constant time performance for such blob values.
The following benchmark is a bit contrived, but illustrates the issue. 10 x 64 KiB blobs are written to the database and then read randomly (Zipfian).
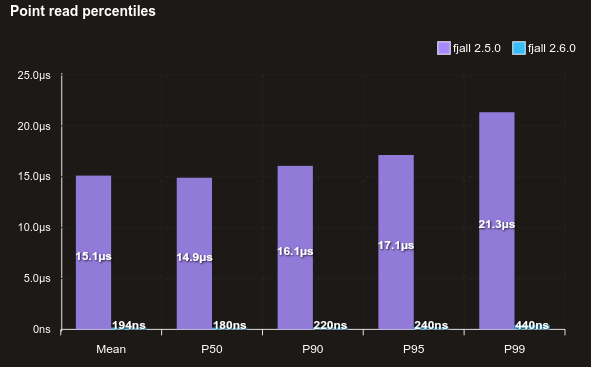
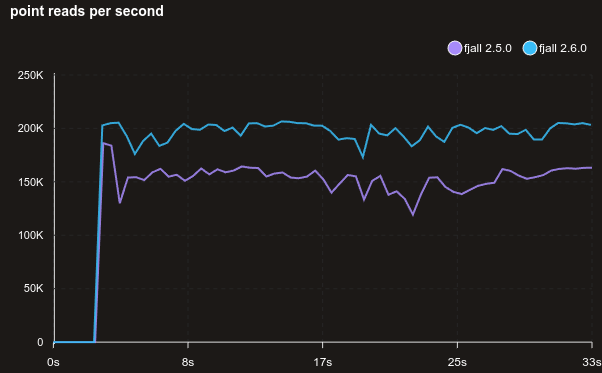
Using a more realistic workload, here are 1 million 1K values that are read randomly (truly random) with no cache. Because the data set is now ~1 GB, not all reads are terminated at the memtable, still reads are about 20% faster.
Compaction performance
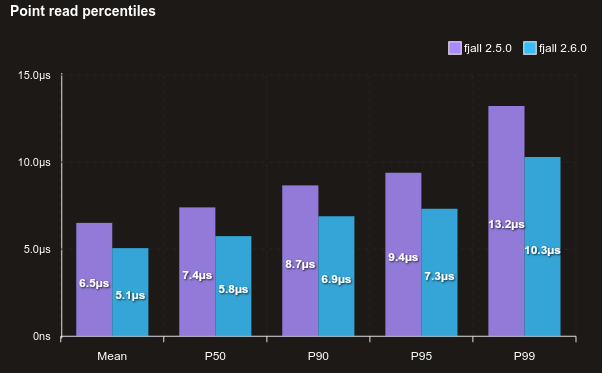
In lsm-tree, compactions need to read an entire disk segment block-by-block, so improving deserialization speeds inadvertently increases compaction throughput.
The following benchmark compacts 10 disk segments with 1 million key-value-pairs (around 24 - 150 bytes per value) each.
Before (2.6.0 without byteview):
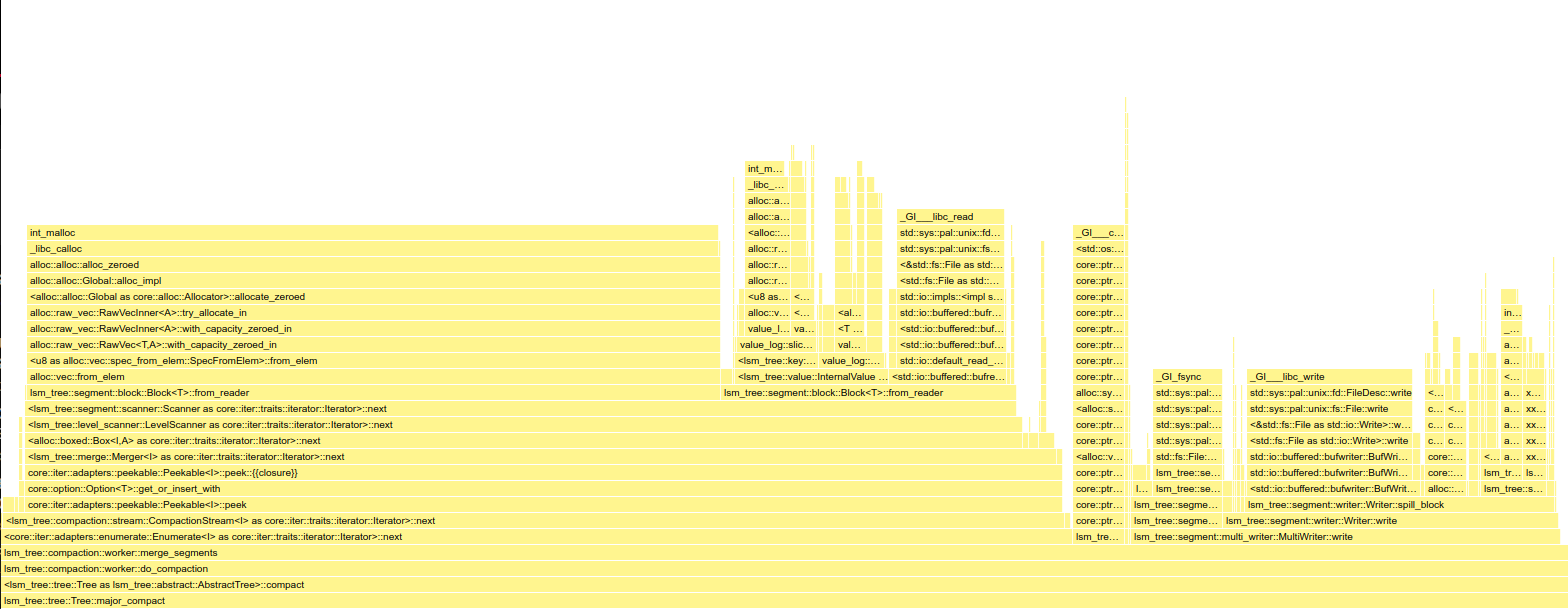
After (2.6.0 with byteview):
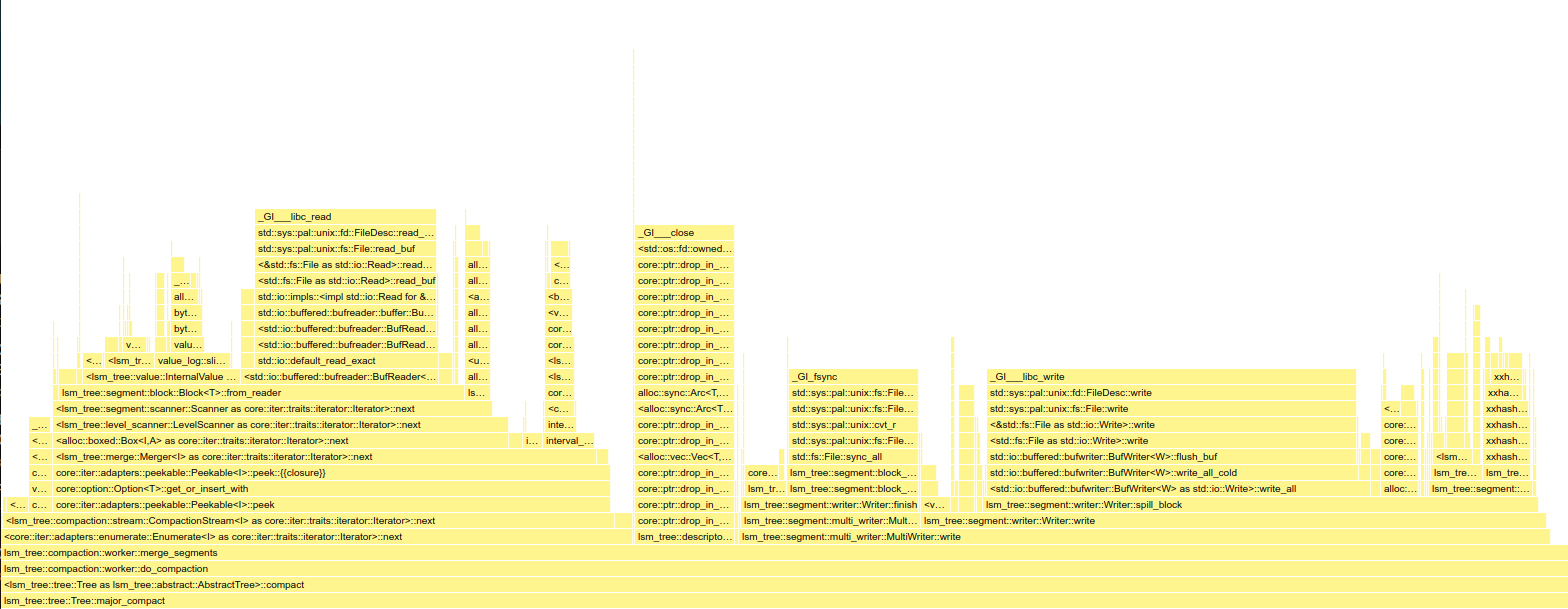
(Open the image in a new tab to zoom into the flame graph)
With Arc<[u8]> around 44% of the runtime is spent in Slice::from_reader because of the superfluous heap allocations, buffer zeroing and memory copies when constructing each Slice.
With ByteView, this stage is reduced to 26%.
Uncached read performance
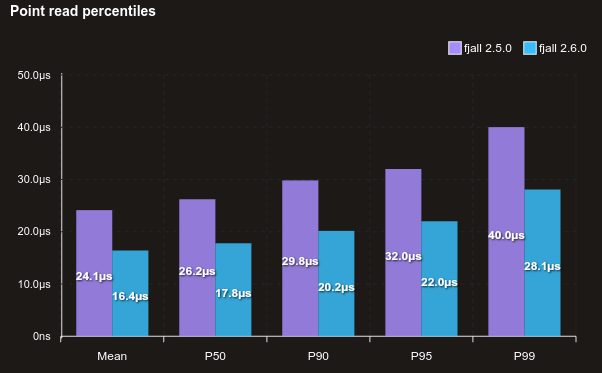
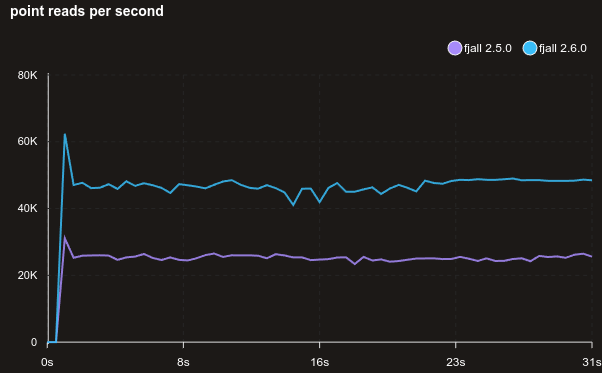
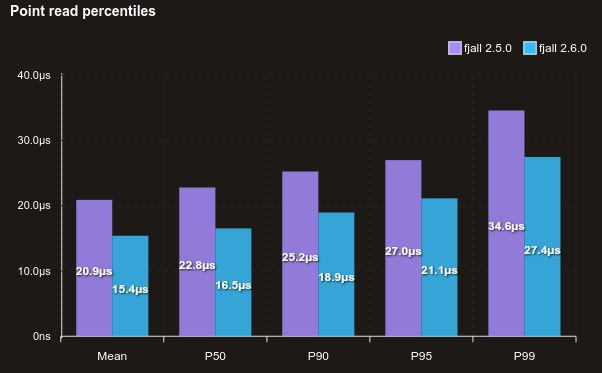
Read performance is generally better across the board, here’s a benchmark reading randomly from 1 million 128-byte values, with no cache:
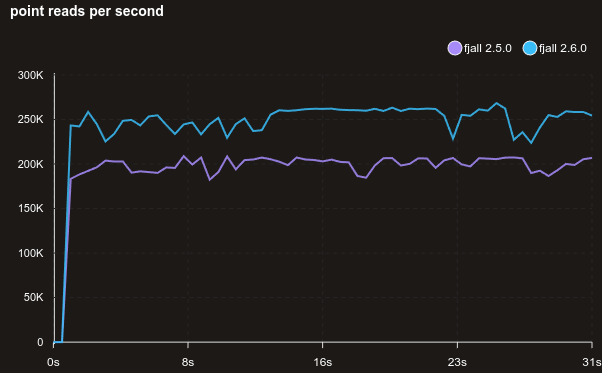
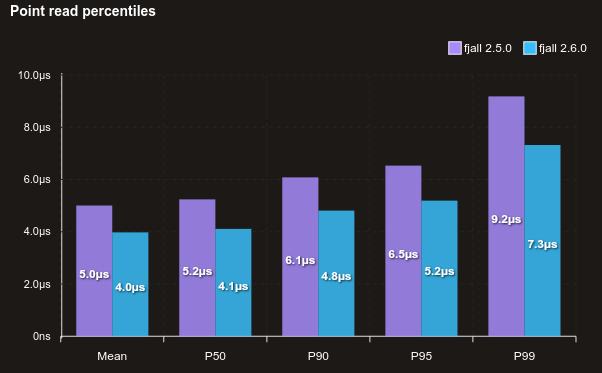
With a block size of 32 KiB (above is 4 KiB):
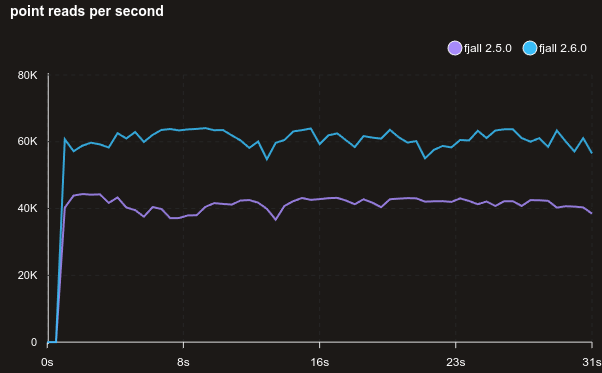
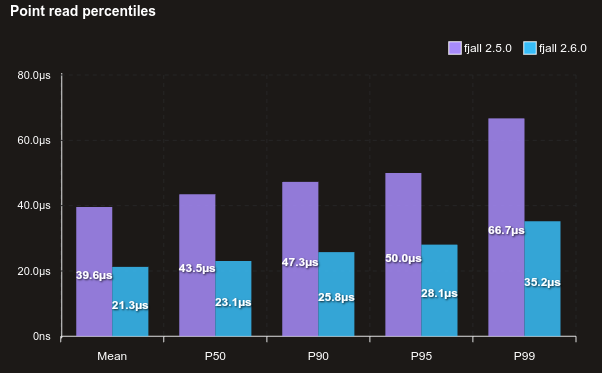
And here’s the same without using jemalloc (but the default Ubuntu system allocator instead):
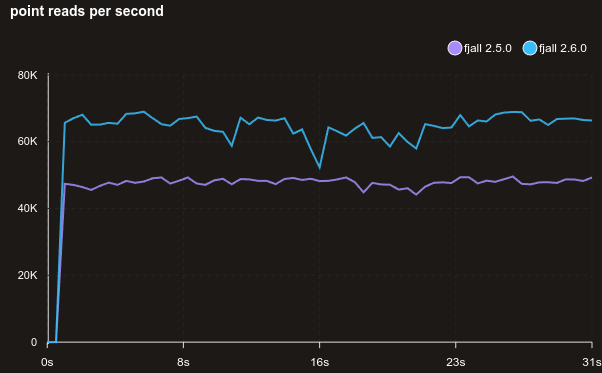
And, for good measure, here is mimalloc:
Other compaction improvements
Until now, compactions used the same read path as a normal read request:
- look into block cache
- if found in cache, load block from cache
- else, load block from disk
However, the possibility of the majority of blocks being cached is slim, so the overhead of looking into the block cache actually did not really help with compaction speeds.
Additionally, the compaction streams did not own their file descriptors, but instead borrowed them from a global file descriptor cache for each block read.
This would also increase overhead because yielding the file descriptor caused the next block read to need an fseek syscall.
Also the compaction stream could not use a higher buffer size (for reading ahead).
That does not mean, compactions cannot profit from I/O caching. The reads still go through the operating system’s page cache, so not every block read may end up performing I/O, though this is at the mercy of the operating system in use.
Now, every compaction stream uses its own file descriptor and does not access the block cache. This makes the read-and-write compaction path much simpler, yielding some great performance boost:
Before (2.5.0):

After (2.6.0):

(Open the image in a new tab to zoom into the flame graph)
MSRV
The minimum supported rustc version has increased from 1.74 to 1.75.
Fjall 2.6
lsm-tree and fjall 2.6 are now available in all cargo registries near you.
Oh, and byteview is MIT-licensed!!
Discord
Join the discord server if you want to chat about databases, Rust or whatever: https://discord.gg/HvYGp4NFFk
Interested in LSM-trees and Rust?
Check out fjall, an MIT-licensed LSM-based storage engine written in Rust.